Формы
Бэкуса-Наура (БНФ).
Как программируют трансляторы? Этот вопрос давно
интересовал меня. Году в 1998 я, программируя функции для обработки строк, сам,
«своим путем», продвинулся «на некоторую глубину» в этом направлении. Но потом
пришел к выводу, что все-таки лучше сперва ознакомиться с тем, что наработано
человечеством в этой области компьютерной науки. Далеко не сразу мне попалась
литература, которую можно было нормально прочитать. То же относится и к статьям
в Интернете. Причем, я бы не сказал, что мне попались отличные источники.
Которые прочитал – и все понял, ничего больше не надо. Нет, то здесь, то там
были рассеяны отдельные крупицы знаний, которые еще надо было перерабатывать и
осмысливать своими мозгами. Однажды я скачал (и распечатал) даже исходник
транслятора Бэйсика. Но заняться им сразу руки не дошли, а потом я с огорчением
обнаружил, что потерял распечатку.
Кстати, пока под транслятором я подразумеваю и
компиляторы, и интерпретаторы.
Оказалось, что в основе программирования трансляторов
лежит целая математическая теория. Раздел не то дискретной математики, не то
теории множеств. И главное здесь – это грамматики и формы Бэкуса-Наура.
В математические определения, связанные с грамматиками, я
здесь вдаваться не буду. Если вам интересно – прочитайте соответствующую книгу
или статью. Скажу только, что прежде всего есть так называемый алфавит – некое
множество символов. Из этих символов составляются некоторые сочетания (можно
назвать их словами). А уже эти сочетания составляют текст (если это грамматика
обычного человеческого языка) или программу (если это грамматика языка
программирования). Текст может быть правильным (то-есть составленным по
правилам этой грамматики) или неправильным. И основная задача теории –
определить, правильный или неправильный этот текст. Правила «кодируются» с
помощью своеобразных конструкций – форм Бэкуса-Наура.
Попробую дать определение этих форм. Каждая форма – это
некоторая строчка.
Есть знак := . Он отделяет левую часть строки от правой.
Есть так называемые «терминалы» - это, грубо говоря, то,
из чего состоит язык. Допустим, человеческий язык состоит из предложений,
предложения – из слов, слова бывают подлежащими и сказуемыми. Слова же в свою
очередь состоят из букв. Предложения, слова, подлежащие и сказуемые, буквы –
это все терминалы. Впрочем, буквы называют еще терминальными символами.
Если же мы имеем строку арифметического выражения, то она состоит из множителей (или делимых-делителей), а также из слагаемых, а они в свою очередь состоят из чисел. Причем слагаемое само может состоять из слагаемых. Например:
1+2+3
Слагаемое 1+2 само состоит из двух слагаемых – 1 и
2. Это – важный пункт.
Терминалы часто как-то «обзываются» - например «множ» или
“factor” (что
вообще говоря должно обозначать одно и тоже – множитель.
И, наконец, есть «нетерминалы» - < и >. Они как
скобки обрамляют некоторые терминалы.
Есть еще знак | - он разделяет несколько альтернативных
терминалов.
Наверное, пока непонятно, но все нужно смотреть и
постигать на примерах.
Это все самый «простейший» вариант форм Бэкуса-Наура.
Есть и усложнения. Допустим, некоторые конструкции (в правой части строки)
можно взять в квадратные скобки ([ … ]). Это означает, что конструкция может
отсутствовать (то-есть или присутствует один раз, или отсутствует). А если без
таких скобок – значит присутствует строго один раз.
Есть и фигурные скобки ({ … }). «Обрамленная» ими
конструкция повторяется некоторое (возможно нулевое) количество раз.
Встречал я и такие скобки: {/ … /}. Это означает
повторение 1 или большее количество раз (то-есть ненулевое количество).
Есть и другие разночтения в определениях форм. Бывает,
например, что опускают нетерминалы < и >.
Кстати, насчет скобок. Я бы ввел еще один вид скобок,
означающий повторение определенное количество раз. Обозначение может быть
таким:
{5/ … /5} – повторение 5 раз. В некоторых случаях
это может оказаться полезным.
Теперь приступим к примерам.
1)
Дадим определение
идентификатору с помощью БНФ (то-есть форм Бэкуса-Наура):
<Буква> := A|B|C|…|Z
<Цифра> := 0|1| … |9
<Идент> := <Буква> {<Буква>|<Цифра>}
Основная идея такого формализма понятна, я надеюсь. Идентификатор начинается обязательно с буквы, а дальше идет некоторое количество букв или цифр. В этом смысл вышеприведенных 3-х строк.
Примеры идентификаторов:
A B
A1 B2C3 DA123
Отметим тут же, что всегда есть «самый главный» терминал (и,
соответственно, главная строка, в левой части которой он находится),
соответствующий тому объекту, который мы исследуем. В данном случае исследуем
мы идентификатор, а самый главный терминал – это «Идент».
2)
Грамматика целых
чисел без знака:
<число> := <цифра>|<цифра><число>
<цифра> := 0|1|2|…|9
Обратим внимание, что терминал «число» встречается в первой строке 2 раза.
Это важный момент. В дальнейшем он приведет к появлению рекурсии (когда мы
будем программировать).
3) Формула с плюсами и минусами без скобок.
<формула> := <число>|<формула><знак><число>
<знак> := +|-
Что такое число – это можно было бы продолжить, приписывая строки примера
2.
Можно было бы записать и такую форму для этого случая:
<формула> :=
<слаг> {<add_знак><слаг>}
<слаг> := <число>
<add_знак>
:= +|-
А если и числа, и переменные, то:
<формула> :=
<слаг> {<add_знак><слаг>}
<слаг> := <число>|<переменная>
<add_знак>
:= +|-
4) Формула с плюсами и минусами со скобками.
<формула> := <op>|<формула><знак><число>
<op>
:= <число>|(<формула>)
<знак> := +|-
Обратим внимание, что во второй
строке появились скобки. «Op» – это некоторый промежуточный терминал,
введенный для удобства.
5) Формула с плюсами и минусами, а также с умножением и делением без
скобок. Входят в формулу не только числа, но и переменные.
<формула> := <слаг> {<add_знак><слаг>}
<слаг> := <множ>{<mul_знак><множ>}
<множ> := <число>|<переменная>
<add_знак> := +|-
<mul_знак>
:= *|/
То-есть, самые крупные блоки, которые мы выделяем из строки с формулой –
это слагаемые. Заметим, что этим определяется самый низший приоритет операций
сложения-вычитания. Обратим внимание еще на то, что левое слагаемое уже не
состоит из вложенных слагаемых, в отличие от правого.
6)
Формула с плюсами и
минусами, с умножением и делением без скобок, а также с унарным плюсом-минусом
(причем унарный знак может присутствовать перед числом или переменной лишь в
единственном числе).
<формула> :=
<слаг> {<add_знак><слаг>}
<слаг> := <множ_со_знаком>{<mul_знак><множ_со_знаком>}
<множ_со_знаком> := [<add_знак>]<множ>
<множ> := <число>|<переменная>
<add_знак>
:= +|-
<mul_знак>
:= *|/
7) Формула с плюсами и минусами,
умножением и делением и со скобками.
<формула> := <слаг> {<add_знак><слаг>}
<слаг> := <множ>{<mul_знак><множ>}
<множ> := <число>|<переменная>|(<формула>)
<add_знак>
:= +|-
<mul_знак> := *|/
8) Добавляем функции (встроенные) одного переменного (пусть это будут
для примера sin и cos).
<формула> := <слаг> {<add_знак><слаг>}
<слаг> := <множ>{<mul_знак><множ>}
<множ> := <число>|<переменная>|(<формула>)|<Func>(<формула>)
<add_знак>
:= +|-
<mul_знак> := *|/
<Func> := sin|cos
Диаграммы
Вирта.
Есть еще альтернативный подход к описанию правил грамматики. Это диаграммы Вирта. Вирт, кстати, это создатель языка Паскаль.
Описания того, что есть что в диаграммах Вирта, я нашел в Интернете. Но скажу честно, понимается это с трудом. Опишу вкратце на словах. Нечто, обведенное кружком – это терминальный символ. Есть еще нечто, заключенное в прямоугольник – это «постоянная группа терминальных символов, определяющая название лексемы, ключевое слово и др.». То-есть в кружок и прямоугольник заключаются терминалы (то, что мы имели ввиду под терминалами в формах Бэкуса-Наура).
Есть еще «нетерминальный символ, определяющий название правила». Это, по-видимому, то, что в формах Бэкуса-Наура мы ставили в левой части строки, слева от знака «:=».
И есть еще соединительные линии. Они «обеспечивают связь между терминальными и нетерминальными символами». Эти линии расходятся, потом сходятся снова, проходя через кружки и прямоугольники. Иногда образуют циклические петли, касающиеся основной горизонтальной линии.
Диаграмма состоит из нескольких «рисунков», также, как БНФ – из нескольких строк. На одном рисунке всегда есть основная горизонтальная линия, в начале которой написано название правила. Это аналог одной строки из формы Бэкуса-Наура. Если далее линия раздваивается, то это аналог выбора одной из двух альтернатив в БНФ (напомню, что эти альтернативы разделяются знаком | ). Если же есть зацикленная линия (петля), касающаяся основной линии, то это аналог рекурсивной части строки Бэкуса-Наура, то-есть часть этой строки (справа) совпадает с левой частью строки. Если есть несколько петель (рядом или одна над другой), то их аналоги в БНФ будут разделятся знаком |.
Поясним это все примером диаграммы из трех строк (трех рисунков), описывающей идентификатор (грамматику идентификатора). Приведем сперва форму Бэкуса-Наура для этого идентификатора, отличающуюся, кстати, от уже приведенной выше. Она записана без использования скобок.
<Буква> := A|B|C|…|Z
<Цифра> := 0|1| … |9
<Идент> := <Буква> |<Идент> <Буква>|<Идент> <Цифра>
Теперь – диаграмма из 3-х строк:
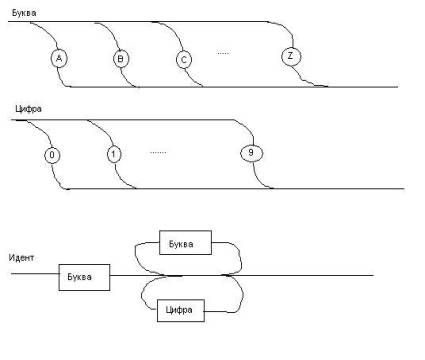
Отметим, что третью строку диаграммы можно нарисовать и так:
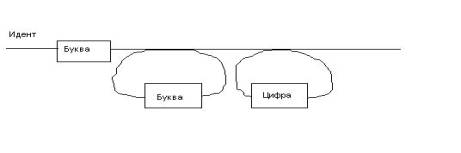
На мой взгляд, принцип построения диаграмм Вирта достаточно понятен. Хотя,
возможно, что-то из теории я и упустил, поскольку изучал этот материал по
довольно отрывочной информации.
Взаимное соответствие между формой Бэкуса-Наура и программой (то-есть программирование транслятора по заданной БНФ).
Теперь мы подходим к самому главному моменту. Как, имея форму Бэкуса-Наура,
составить программу? Допустим, форму, соответствующую некоторому языку (языку
арифметических формул, например), мы составили.
Правила соответствия БНФ-Program такие:
1)Каждому терминалу, стоящему слева от «:=» (по крайней мере, тому, который
может состоять из нескольких символов – такие мы брали в угловые скобки),
соответствует функция в общей программе. То-есть, уточняю, «мелким» терминалам
(таким как знак сложения, допустим, или цифра) функцию можно не сопоставлять.
Но таким, как <Формула>, <Множитель>, <Слагаемое> -
соответствующую функцию сопоставлять нужно.
2)Каково же будет «наполнение» этих функций? То-есть их внутренняя начинка? Когда мы идем по правой
части строки формы (то-есть правее от «:=») слева направо и встречаем «крупный»
терминал (<Множитель>, <Слагаемое>), мы записываем внутри нашей
функции (которую сейчас мы заполняем операторами) соответствующий вызов
функции. Далее – фигурным скобкам (повторению ноль или более раз) будет
соответствовать оператор цикла while. Условием этого цикла скорее всего будет наличие
знака математической операции, который стоит первым в скобке (опять таки
вероятнее всего). Если же скобки квадратные (действие ноль или один раз), то им
соответствует условный оператор if.
Если в правой части строки БНФ есть ряд частей, разделенных вертикальной
палочкой (| - знак альтернативы), то каждой такой части должен соответствовать
свой участок кода внутри нашей функции. Реализовать такую «архитектуру» можно с
помощью if
или if-else. Можно применять и
другие способы
3)Наша программа, которую мы
транслируем, должна выполнять некоторую полезную работу, например складывать и
перемножать числа, чтобы получить
конечное значение формулы. Насчет этого «пункта» в формах Бэкуса-Наура не
говорится ничего. Но в программе-трансляторе эти куски кода должны быть
обязательно. Можно дать совет вставлять их и испытывать методом проб и ошибок.
4)Еще важный пункт – при движении по правой части
строки мы переходим от одного терминала к другому. Внутри функции этому соответствует
вызов сканера для получения следующей лексемы после очередного «внутреннего»
вызова функции. Но нужно учесть, что некоторые вызовы сканера может оказаться
удобным «прятать» внутри вызываемых внутренних функций, а не в теле самой
функции (которую мы пишем в данный
момент). Итак, движению слева направо (по правой части строки) от одного
терминала к другому соответствуют вызовы сканера в программе.
Уточняю – сканер это функция или подпрограмма (функция
программы-транслятора), которая просматривает весь текст программы
(транслируемой) и делит его на так называемые лексемы. Лексема – это число, или
имя переменной, или знак операции, или название оператора (if, while), или что другое
(имя функции например). Обычно вызов сканера «поставляет» очередную лексему в
программе.
Пример соответствия строки БНФ и функции (язык Си):
<expr> := <term>{<addop><term>} – это строка
БНФ.
Теперь функция:
expr( )
{
term( );
while(*Lex==’+’)
/* Обратите внимание на соответствие <addop> и проверки на наличие знака
+ в условии оператора цикла */
{
NextLexema( ); /* Вызов сканера */
Term( );
}
}
Кстати, вышеприведенные рассуждения относятся не только к
программам на языке Си, но и к любым языкам, поддерживающим рекурсивные функции
(а также операторы цикла и условные операторы, естественно).